
近日,国际计算机视觉领域顶级会议ICCV 2025(International Conference on Computer Vision) 在美国夏威夷圆满落幕。作为全球计算机视觉领域最具影响力的学术盛会之一,ICCV每两年举办一次,与CVPR、ECCV并称为“计算机视觉三大顶会”,吸引了全球顶尖高校与科技企业参与其中。
本届ICCV会议举办的VQualA(Visual Quality Assessment Competition)研讨会设有多个挑战赛,涵盖AIGC视频、人脸图像质量评估、短视频热度预测等前沿领域。华东师范大学通信与电子工程学院孙伟课题组凭借创新技术方案,在人脸图像质量评估(FIQA)与短视频热度预测(EVQA-SnapUGC)两个赛道中均荣获冠军,展现了强劲的科研实力与国际竞争力。

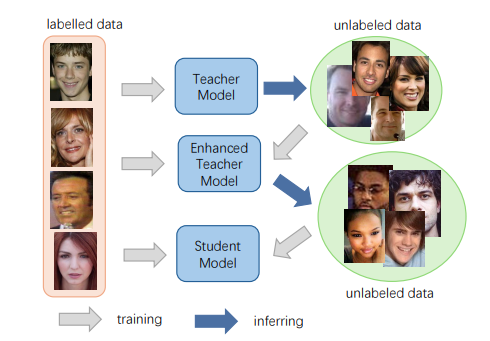
人脸图像质量评估(FIQA)赛道:自训练与蒸馏打造高效人脸质量评价模型
在由美国Snap Research团队主办的FIQA赛道 中,孙伟课题组的论文 《Efficient Face Image Quality Assessment via Self-training and Knowledge Distillation》提出了兼顾性能与效率的创新方案。
该方案针对真实应用中对人脸图像质量快速筛查的需求,提出了 “教师–学生双阶段自训练与知识蒸馏框架”。研究团队首先构建高性能教师模型,利用海量无标注人脸数据进行自增强学习,再通过知识蒸馏训练轻量级学生模型,实现了性能与效率的双赢。最终模型在显著降低计算复杂度的同时,依然保持了与大模型相当的质量评价能力,为实际应用提供了高效可靠的解决方案。
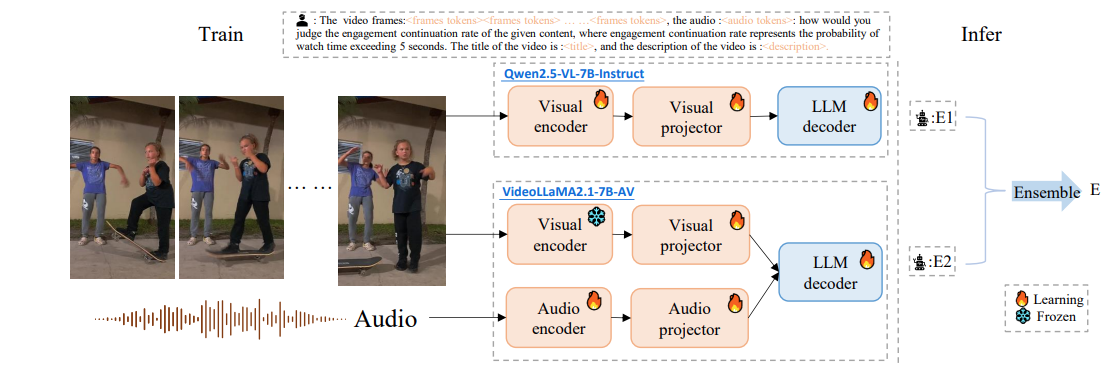
短视频热度预测(EVQA-SnapUGC)赛道:大模型赋能“视频能否爆火”的智能判断
在另一项由美国Snap Research团队主办的EVQA-SnapUGC赛道 中,孙伟课题组的论文 《Engagement Prediction of Short Videos with Large Multimodal Models》 提出了基于多模态大模型的短视频热度预测方案。
该方案旨在预测用户在短视频平台上观看超过5秒的概率,以此作为衡量视频内容吸引力与推荐算法效率的重要指标。课题组提出的方案首次将多模态大模型(Large Multimodal Models, LMMs)深度应用于视频参与度预测,构建了由Qwen2.5-VL与Video-LLaMA2两个视觉语言模型组成的双模型集成框架,融合视频图像、文本与音频三种模态,实现了端到端的视频热度建模,显著提升了预测的准确度与泛化能力。
此次在国际学术竞赛中斩获两项冠军,体现了学院科研团队锐意创新、追求卓越的精神风貌。学院将继续鼓励师生勇于探索、不断突破,在国际学术舞台上展现中国高校科研的力量。
